Tolerancia a Fallas con RSM.
En esta sección se presentan las principales características del RSM
Protocolo de Recuperación.
El mecanismo básico de RSM para permitir la recuperación frente a fallas, es el de almacenar los datos del punto de recuperación;, en un bloque de memoria, manteniendo dos copias de éste último. Cuando un nuevo punto de recuperación se establece, las dos copias (bloques de memoria) contienen los mismos datos.
En la medida en que las aplicaciones son ejecutadas, los datos se van actualizando en uno de los bloques de memoria. De esta manera, el otro bloque mantiene el estado de la memoria en el momento del punto de recuperación.
Como se necesita almacenar sólo un punto de recuperación, solamente es necesario tener dos bloques de memoria. Luego, cuando se realiza un "commit", el bloque que contiene los datos actualizados es copiado al otro bloque, estableciéndose un nuevo punto de recuperación.
Así, el RSM puede ser implementado con dos bancos de memoria del mismo tamaño, uno conteniendo los valores actuales y el otro los valores de recuperación.
Para identificar un punto de recuperación, el protocolo:
- Detecta y almacena la ocurrencia de comunicación entre procesadores, lo cual implica que ambos CPUs comparten datos entre sí.
- Se usa esta información para sincronizar el protocolo de recuperación.
Relación de Dependencia.
|
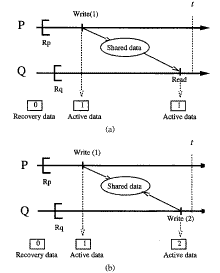
Existen dos tipos de interacciones entre procesadores que permiten identificar un punto de recuperación: leer después de escribir (read after write) y escribir después de escribir (write after write).
Ambas interacciones pueden apreciarse en la figura. En la parte superior se produce un evento de read after write, mientras que en la inferior se tiene un evento de write after write.
|
|
El efecto de estas interacciones es una relación de dependencia entre procesadores.
Luego, un procesador P depende de otro procesador Q si:
- La recuperación de P requiere la recuperación de Q.
- Hacer "commit" del procesador Q requiere que P también haga "commit".
En el evento de read after write (ver figura) el procesador P depende de Q, tan pronto Q lee el valor escrito por P.
En el evento de write after write, Q depende de P, tan pronto Q escribe sobre el valor que P ya ha escrito.
Operación de Recuperación del Protocolo.
Obviamente la dependencia entre procesadores es transitiva.
Así se definen grupos de dependencia (procesadores que tienen relaciones de dependencias entre sí).
Luego, cuando un procesador, en caso de falla, realiza una operación de recuperación (volver al punto de recuperación), el RSM computa la transitividad de la dependencia de procesadores, obteniendo así el grupo de dependencia. Entonces RSM informa (mediante interrupciones) a los miembros del grupo que deben participar en la operación de recuperación. De esta manera, sólo los procesadores involucrados en esta operación deben volver al punto de recuperación (roll back), mientras que el resto puede seguir con su ejecución normal. Así se minimiza el retardo en la ejecución introducido por las operaciones de recuperación.
Almacenamiento de las Comunicaciones entre Procesadores.
Cuando un bloque de memoria es accesado por un procesador, el RSM necesita la siguiente información, de manera de poder almacenar las dependencias entre procesadores:
- La identidad del procesador que está realizando el acceso. (esta información está disponible en la mayoría de los buses)
- El tipo de acceso (escritura o lectura)
- La identidad del último procesador que ha escrito en este bloque (escritor activo del bloque), en caso de existir.
El tamaño del bloque de memoria debe ser al menos del mismo tamaño que la línea de cache, esto es, la mínima unidad de transferencia en el bus.
Para almacenar las dependencias, el RSM debe detectar todos los accesos en el bus que modifiquen datos, de manera de modificar al escritor activo del bloque.
Actualización del campo "Escritor Activo".
De modo de mantener el campo de "escritor activo" (ver Implementación de RSM) del bloque, el RSM debe ser capaz de detectar cualquier cambio de la identidad procesador que esta escribiendo en un bloque. Un cambio del escritor activo sólo puede ocurrir cuando un procesador escribe en un bloque por primera vez o cuando debe transferir los datos de su cache a memoria.
Almacenamiento de Dependencias.
Como se expuso anteriormente, un procesador depende de otro cuando ocurre un evento read after write o write after write. De modo de calcular los grupos de dependencia, para poder realizar el proceso de roll back (volver al punto de recuperación) en caso de falla, la información es almacenada dentro del RSM en una matriz boleana de n x n, donde n es el número máximo de procesadores en la arquitectura. Un elemento M(i,j) de la matriz contendrá un valor verdadero cuando el procesador Pi depende del procesador Pj.
Protocolo de Generación de Commit.
Este protocolo consta de tres fases, en las cuales los procesadores son los participantes y el módulo RSM es el coordinador. Las tres fases del protocolo son las siguientes:
- Inicialización del protocolo
: Un procesador que desea hacer commit sobre un punto de recuperación, debe asegurarse que los datos que ha modificado en su cache sean actualizados en el módulo RSM. Para ello, envía todos los datos internos del procesador (registros, contadores de programa, etc.) al RSM.
Una vez que esta operación ha sido realizada, el procesador envía un comando do_commit al RSM y espera una interrupción de vuelta que le indica que la operación ha sido realizada con éxito.
- Segunda Fase
: Cuando el módulo RSM recibe un comando do_commit de un procesador P, lo primero que debe hacer es calcular el grupo de dependencia del procesador P. Este grupo de procesadores deben realizar la operación do_commit, junto con P.
Una vez calculado el grupo de dependencia, se envía una interrupción prepare_to_commit a cada uno de los miembros del grupo, de modo de avisarles que deben comenzar con el protocolo de generación de commit en su primera fase.
Puede suceder que mientras se envía la interrupción prepare_to_commit a los distintos procesadores, otros pueden pasar a ser parte del grupo de dependencia. Es por esto que el RSM debe calcular, durante el tiempo que dure el protocolo, constantemente y en forma paralela el grupo de dependencia, para que los nuevos procesadores que entran a este grupo también reciban la interrupción prepare_to_commit.
- Tercera Fase
: Una vez que todos los procesadores participantes del protocolo han enviado el comando do_commit, el RSM entra en la tercera fase del protocolo. Este consta de las siguientes tareas:
- Descartar el bloque de memoria donde se almacenaban los datos relativos al punto de recuperación anterior y copiar los nuevos datos.
- Romper las dependencias entre los procesadores participantes. Esto es, poner en falso los elementos M(i,j) de la matriz, para todo i, j : identificadores de los procesadores participantes.
- Enviar una interrupción commit_done a todos los procesadores pertenecientes al grupo de dependencia, de manera que puedan continuar con la ejecución de las aplicaciones.
Protocolo de Recuperación.
En caso de falla, el procesador que falló pondrá en el bus una interrupción que indica su falla (no siempre es factible que este hecho ocurra). Dicha interrupción es detectada por algún procesador que se mantiene funcionando y envía el comando do_rollback(i) al módulo RSM, donde i es el identificador del procesador que ha fallado.
Una vez recibido el comando do_rollback(i), el RSM debe calcular el grupo de dependencia del procesador i. Dicho grupo debe volver al punto de recuperación, ya que este es un estado consistente.
Cuando se ha calculado el grupo de dependencia, el módulo RSM debe realizar básicamente las mismas operaciones que en la fase tres del protocolo de generación de commit :
- Copiar el bloque de datos de respaldo al bloque de memoria activa.
- Eliminar dependencias entre procesadores, reseteando, donde corresponda, la matriz de dependencia.
- Enviar a cada uno de los procesadores pertenecientes al grupo de dependencia una interrupción de roll_back, para que descarten la información contenida en sus caches y registros y copien la información correspondiente del bloque de memoria activa.
Una vez terminadas las tareas anteriores, el sistema debería volver a un estado consistente